사이킷런 샘플 데이터
| 내용 | 로드 명령 |
| 보스턴 주택가격 | load_boston() |
| 붓꽃 품종 | load_iris() |
| 손글씨 숫자 데이터 | load_digits() |
| 와인종류 | load_wine() |
| 운동능력 데이터세트 | load_linnerud() |
| 당뇨병 진행상황 | load_diabetes() |
| 유방암 음성/양성 | load_breast_cancer() |
붓꽃 품종 데이터 세트 살펴 보기
| 데이터이름 | 내용 |
| data | 학습용데이터 |
| feature_names | 특징 이름 |
| target | 타깃값 |
| target_names | 타깃이름 |
| descr | 데이터세트에 관한 설명 |
예제로 살펴 보기
from sklearn import datasets
iris = datasets.load_iris()
print(iris){'data': array([[5.1, 3.5, 1.4, 0.2],
...
[5.9, 3. , 5.1, 1.8]]),
'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
...
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]),
'frame': None,
'target_names': array(['setosa', 'versicolor', 'virginica'], dtype='<U10'),
'DESCR': ..., 'data_module': 'sklearn.datasets.data'}
- 특징이름 살펴 보기
iris.feature_names['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']특징을 살펴 보면, 꽃받침 길이, 꽃받침 넓이,꽃잎 길이, 꽃잎 넓이 임을 알 수 있다.
데이터를 pandas 데이터로 변환
import pandas as pd
df = pd.DataFrame(iris.data)
df.head()5개의 0(sepal length),1(sepal width),2(petal length),3(petal width) 의 데이터를 확인 해 보자.
여기서 맨 위의 0,1,2,3 은 열(column) 은 특성(feature),속성(attribute),변수(varible),필드(field) 라고도 한다.

다음으로 열 이름에 특징명을 설정하자
df.columns = iris.feature_names # 열 이름 설정
df.head()
다음으로 데이터에 target을 추가하자.
df["target"]=iris.target
df.head()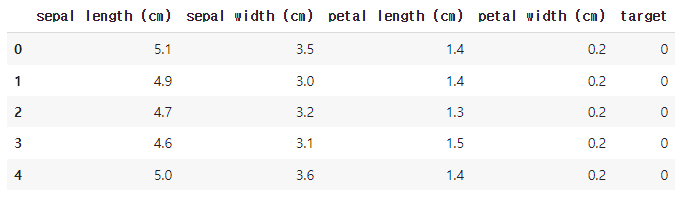
여기서 target은 0 뿐인데 앞쪽 데이터가 setosa 임을 의미한다.
데이터 그래프로 나타내기
import seaborn as sns
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import proj3d
sns.pairplot(df, hue="target")
plt.show()
4*4 의 16개의 그래프를 확인해 볼 수 있다.
이것을 세가지 품목을 꽃받침 폭을 기준으로 히스트그램을 그려서 살펴 보자.
히스토 그램을 그리기 위해 matplotlib 을 import 한다.
import matplotlib.pyplot as plt
df0=df[df["target"]==0] #setosa 인 경우만 1 아니라면 0
df1=df[df["target"]==1] #versicolor 인 경우만 1 아니라면 0
df2=df[df["target"]==2] #virginica 인 경우만 1 아니라면 0
plt.figure(figsize=(5,5)) #크기가 5*5 인 사이즈로 그리자.
df0["sepal width (cm)"].hist(color="b",alpha=0.5) #sepal width (cm) 의 값으로 blue 로 투명도 0.5
df1["sepal width (cm)"].hist(color="r",alpha=0.5) #sepal width (cm) 의 값으로 red 로 투명도 0.5
df2["sepal width (cm)"].hist(color="g",alpha=0.5) #sepal width (cm) 의 값으로 green 로 투명도 0.5
plt.xlabel("sepal width (cm)")
plt.show()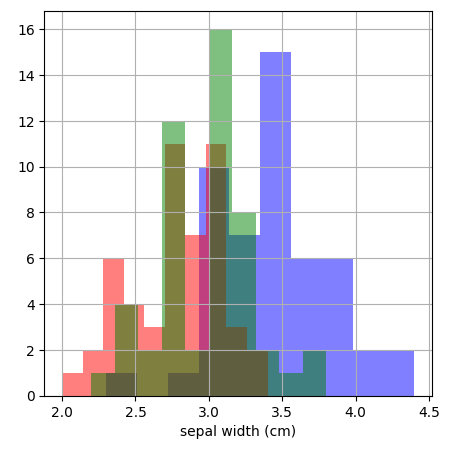
여기서 꽃받침의 폭으로는 겹치는 것이 많은 것을 알 수가 있다.
다음은 두가지 특징을 이용하여 산포도를 그리는 방법을 살펴 보자.
산포도는 데이터프레임의 scatter() 로 그릴 수 있다.
plt.figure(figsize=(5,5))
plt.scatter(df0['sepal width (cm)'],df0['sepal length (cm)'],color="b",alpha=0.5) #x축을 sepal width (cm),y축을 sepal length (cm)
plt.scatter(df1['sepal width (cm)'],df1['sepal length (cm)'],color="r",alpha=0.5) #x축을 sepal width (cm),y축을 sepal length (cm)
plt.scatter(df2['sepal width (cm)'],df2['sepal length (cm)'],color="g",alpha=0.5) #x축을 sepal width (cm),y축을 sepal length (cm)
plt.xlabel('sepal width (cm)')
plt.ylabel('sepal length (cm)')
plt.show()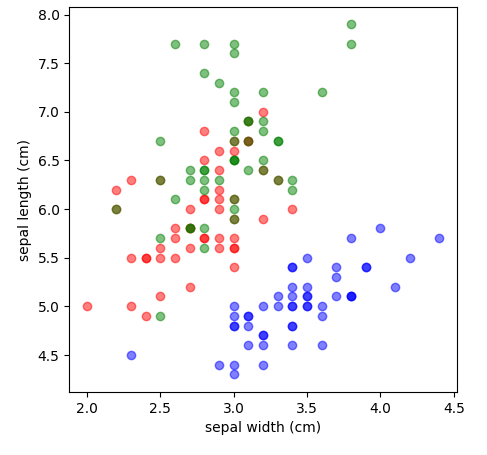
이렇게 그려 보니 r과 g 는 중복이 발생하지만 b는 거의 중복이 발생하지 않는 것을 알 수 있다.
이것은 2차원으로 살펴 보았기 때문에 r과 g의 중복이 발생한다.
그렇다면 특징량을 3개로 해서 3차원으로 그려 보면 어떻게 될까?
마찬가지로 scatter를 이용하여 3개의 데이터를 이용하여 3차원으로 그릴 수 있다.
위의 코드에서 petal length 를 추가하여 그려 보자.
3D 공간을 만들기 위해 fig.add_subplot(projection='3d') 을 사용하여 Axes3D 를 사용하자.
fig=plt.figure(figsize=(5,5))
ax=fig.add_subplot(projection="3d")
plt.scatter(df0['sepal width (cm)'],df0['sepal length (cm)'],df0['petal length (cm)'],color="b",alpha=0.5) #x축을 sepal width (cm),y축을 sepal length (cm)
plt.scatter(df1['sepal width (cm)'],df1['sepal length (cm)'],df1['petal length (cm)'],color="r",alpha=0.5) #x축을 sepal width (cm),y축을 sepal length (cm)
plt.scatter(df2['sepal width (cm)'],df2['sepal length (cm)'],df2['petal length (cm)'],color="g",alpha=0.5) #x축을 sepal width (cm),y축을 sepal length (cm)
ax.set_xlabel('sepal width (cm)')
ax.set_ylabel('sepal length (cm)')
ax.set_zlabel('petal length (cm)')
plt.show()
아직도 빨강과 그린이 섞여 있는 것을 알 수 있다.
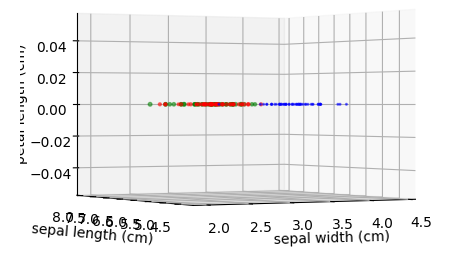
ax.view_init(세로각도,가로각도)를 이용해서 시점을 바꿔서 확인해 볼 수도 있다.
fig=plt.figure(figsize=(5,5))
ax=fig.add_subplot(projection="3d")
plt.scatter(df0['sepal width (cm)'],df0['sepal length (cm)'],df0['petal length (cm)'],color="b",alpha=0.5) #x축을 sepal width (cm),y축을 sepal length (cm)
plt.scatter(df1['sepal width (cm)'],df1['sepal length (cm)'],df1['petal length (cm)'],color="r",alpha=0.5) #x축을 sepal width (cm),y축을 sepal length (cm)
plt.scatter(df2['sepal width (cm)'],df2['sepal length (cm)'],df2['petal length (cm)'],color="g",alpha=0.5) #x축을 sepal width (cm),y축을 sepal length (cm)
ax.set_xlabel('sepal width (cm)')
ax.set_ylabel('sepal length (cm)')
ax.set_zlabel('petal length (cm)')
ax.view_init(0,240)
plt.show()
'머신러닝 > 3. 머신러닝을 위한 파이썬' 카테고리의 다른 글
| Do it] LLM을 활용한 AI 06-1.GPT 비전에게 이미지 설명 요청하기 (0) | 2025.06.18 |
|---|---|
| 3-2] 사이킷런 샘플 데이터 생성하기 (0) | 2023.12.10 |
| [혼공분석]13.머신러닝으로 예측하기 (0) | 2023.01.02 |
| [혼공분석]12.통계적으로 추론하기2 (0) | 2023.01.01 |
| [혼공분석]12.통계적으로 추론하기 (0) | 2023.01.01 |