1. 토크나이징이란?
어떤 문장을 일정한 의미가 있는 가장 작은 단어들로 나누는 것을 토크나이징이라고 한다.
한국어 자연어 처리를 하는 파이썬 라이브러리가 여러개 있지만 여기서는 KoNLPy 를 사용하도록 한다.
2. KoNLPy
KoNLPy는 기본적인 한국어 자연어 처리를 위한 파이썬 라이브러리이다.
2.1 Kkma
Kkma 는 꼬꼬마로 발음하며 다음과 같이 사용한다.
from konlpy.tag import Kkma코랩에서 에러 발생시 다음과 같이 꼬꼬마 설치
%%bash
apt-get update
apt-get install g++ openjdk-8-jdk python-dev python3-dev
pip3 install JPype1
pip3 install konlpy형태소 분석기를 사용해 보자.
#꼬꼬마 형태소 분석기 객체생성
kkma = Kkma()
text = "아버지가 방에 들어갑니다."
#형태소 추출
morphs = kkma.morphs(text)
print(morphs)
#형태소와 품사 태그 추출
pos=kkma.pos(text)
print(pos)
#명사만 추출
nouns = kkma.nouns(text)
print(nouns)
#문장 분리
sentences ="오늘 날씨는 어때요? 내일은 덥다던데."
s = kkma.sentences(sentences)
print(s)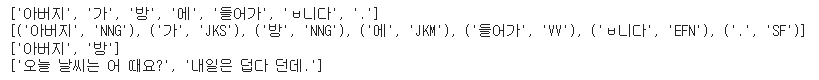
품사태그는 다음의 의미를 가지고 있다.
NNG : 일반명사
JKS : 주격조사
JKM : 부사격 조사
VV : 동사
EFN : 평서형 종결어미
SF : 마침표,물음표, 느낌표
2.2 Komoran
코모란으로 발음하며 다음과 같이 사용한다.
from konlpy.tag import Komoran형태소 분석기 객체만 Komoran 으로 생성하자.
kkma = Komoran()
text = "아버지가 방에 들어갑니다."
#형태소 추출
morphs = kkma.morphs(text)
print(morphs)
#형태소와 품사 태그 추출
pos=kkma.pos(text)
print(pos)
#명사만 추출
nouns = kkma.nouns(text)
print(nouns)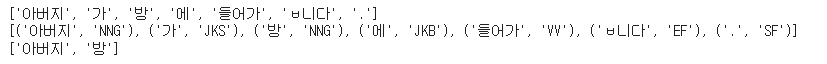
품사태그는 다음의 의미를 가지고 있다.
NNG : 일반명사
JKS : 주격조사
JKB : 부사격 조사
VV : 동사
EF : 종결어미
SF : 마침표,물음표, 느낌표
Komoran 은 Kkma 보다 형태소를 빠르게 분석하여 다양한 품사 태그를 지원합니다.
2.3 Okt
트위터에서 개발한 한국어 처리기로 완전한 형태소 분석을 지향하지 않습니다.
2.4 사용자 사전 구축
챗봇의 데이터 입력단은 인터넷 구어체와 관련이 많습니다.
일반적으로 챗봇 사용자들은 딱딱한 구어체나 문어체를 사용하지 않습니다.
새롭게 생겨나는 단어나 문자은 형태소 분석기에서 인식이 안되는 경우가 많습니다.
따라서 형태소분석기에서 인식하지 못하는 단어들을 직접 추가해 주어야 합니다.
미등록단어 형태소를 분석해 봅니다.
#꼬꼬마 형태소 분석기 객체생성
komoran = Komoran()
text = "우리 챗봇은 엔엘피를 좋아해"
#형태소 추출
morphs = komoran.morphs(text)
print(morphs)
#형태소와 품사 태그 추출
pos=komoran.pos(text)
print(pos)결과는 다음과 같이 나옵니다.
['우리', '챗봇은', '엔', '엘', '피', '를', '좋아하', '아']
[('우리', 'NP'), ('챗봇은', 'NA'), ('엔', 'NNB'), ('엘', 'NNP'), ('피', 'NNG'), ('를', 'JKO'), ('좋아하', 'VV'), ('아', 'EC')]여기서 엔엘피 단어를 분석하지 못했습니다.
코모란에 등록하는 형태는 다음과 같습니다.
다음의 내용을 user_dic.tsv 파일로 저장한 후 다음과 같이 단어와 품사를 Tab 로 구분해 주어야 합니다.
#[단어] Tab [품사]
엔엘피[Tab]NNG그리고 사용자정의 사전을 이용하여 분석해 봅니다.
komoran = Komoran(userdic='./user_dic.tsv')
text = "우리 챗봇은 엔엘피를 좋아해"
#형태소 추출
morphs = komoran.morphs(text)
print(morphs)
#형태소와 품사 태그 추출
pos=komoran.pos(text)
print(pos)['우리', '챗봇은', '엔엘피', '를', '좋아하', '아']
[('우리', 'NP'), ('챗봇은', 'NA'), ('엔엘피', 'NNG'), ('를', 'JKO'), ('좋아하', 'VV'), ('아', 'EC')]위와 같이 정상으로 분석이 되는 것을 확인 하였습니다.
[참고]
한빛미디어 - 처음 배우는 딥러닝 챗봇
'머신러닝 > 12. 딥러닝챗봇' 카테고리의 다른 글
| [딥러닝 챗봇] 챗봇 엔진에 필요한 딥러닝 모델 - LSTM (0) | 2022.06.24 |
|---|---|
| [딥러닝 챗봇] 챗봇 엔진에 필요한 딥러닝 모델 - CNN (0) | 2022.06.21 |
| [딥러닝 챗봇] 챗봇 엔진에 필요한 딥러닝 모델 - 케라스 (0) | 2022.06.21 |
| [딥러닝 챗봇] 텍스트 유사도 (0) | 2022.06.20 |
| [딥러닝챗봇]임베딩 (0) | 2022.06.17 |